notes on f4: Facebook's Warm BLOB Storage System
Here are my notes and summary of f4: Facebook’s Warm BLOB Storage System - Meta Research paper from 2014.
Haystack system uses large files on top of XFS file-system (also known as volumes) as containers for media files used by Facebook users. Volumes contain Binary Large OBjects (BLOBs) and are growing fast, storing them is becoming increasingly inefficient - according to authors of the paper. What does it mean for the storage system to be efficient in this case? How this paper relates to Haystack system?
Haystack was designed to maximize throughput and maintains 3 replicas per logical volume. Additionally, it uses RAID-6 (replication factor of 1.2) on each storage node which gives final replication factor of 3.6. This is a lot of storage overhead.
Efficiency is measured as the replication-factor of BLOBs with relation to system throughput. In other words, it is not efficient to have high replication factor for data which is rarely accessed. By examining usage patterns of BLOBs they could categorise BLOBs into hot and warm. Then they could isolate warm BLOBs in specialized warm BLOBs storage system. They named it f4, it lowers replication-factor of warm BLOBs from 3.6 to 2.8 or 2.1 while remaining fault-tolerant and able to support the lower throughput requirements.
This sounds exciting. Let’s dive into details.
The Case for warm storage
First, they have observed that BLOBs access frequency drops with BLOB age. Since volumes are replicated three times, if we could get rid of some of the replicas for warm BLOBs we could save a lot of storage space. Getting replication down will inevitably bring throughput down though. So how to do it without hurting throughput? Well, actually it’s easier to answer different question: what are throughput requirements for warm BLOBs?
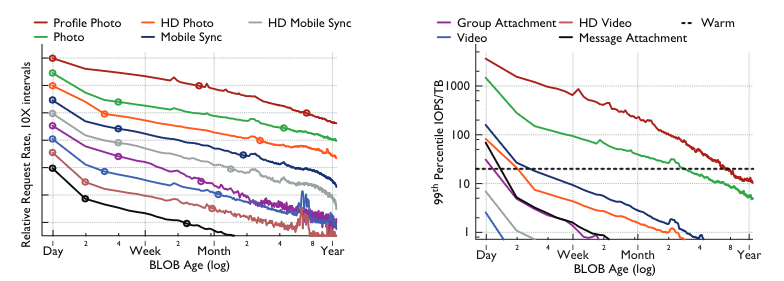
They have measured what is the relative request rate by BLOB age and BLOB type. They have also measured IOPS/TB load of data per BLOB age for each BLOB type. Knowing that we can compare throughput requirements with the throughput of the system and see when BLOBs of given type can move to warm BLOBs storage system. Considered f4 system has 4TB disks capable of delivering 80 IOPS at required latency, and so we have 20 IOPS/TB as limit for warm BLOBs. This yields an age of one month for most type of BLOBs as delimiter between hot and warm zones and 3 months for photos.
f4 architecture
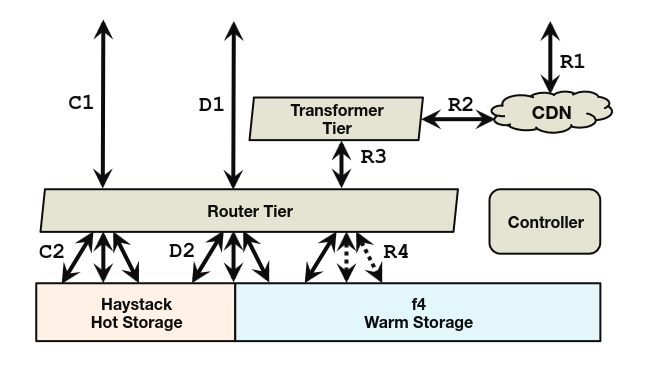
As we can see f4 is a separate system from Haystack. Router tier hides storage implementation from it’s clients (web tier or caching stack). I’ll skip details about Haystack since I’ve already covered it in post about Haystack.
Cell
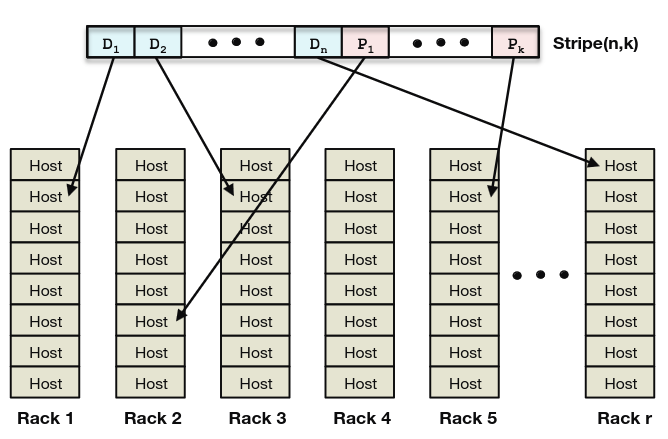
Cell is located in one data center and is compromised of homogeneous hardware: 14 racks of 15 hosts with 30 4TB drives per host. It stores a set of immutable volumes and are resilient to disk, host, and rack failures.
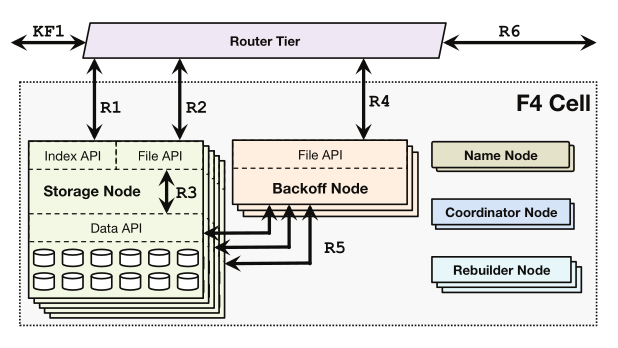
Cell uses distributed erasure coding to store volumes and has replication factor of 1.4 with Reed-Solomon(10, 4) coding. Before we dive into details here is how Reed-Solomon coding works. It’s a way of encoding data blocks with parity blocks in such a way that we can recover original data blocks from any subset of data and parity blocks. For example, if we have 10 data blocks and 4 parity blocks we can recover original data blocks from any 10 blocks out of 14. This is called RS(10, 4) coding and has replication factor of 1.4.
If each data block is distributed to a different rack, host and disk, cell can tolerate failure of max 4 hosts or 4 racks or 4 disks. Note how RS(10, 4) is effectively replacing RAID-6 and achieves fault tolerance spanning over entire cell instead of single host. The price for it is increased recovery and rebuild times since now they need to happen over network instead of local disk. In fact, they have constrained block size to 1GB to keep rebuild times reasonable.
It seems to me that they decided not to use RAID-0 since they treat host and disk failures as independent events, otherwise RAID-0 would make disk a single point of failure for entire host. Possibly this choice gives better fault tolerance characteristics - not in terms of worst case scenario but in terms of percentage of unavailable data per failure unit.
At the beginning cells were replicated to a different data center and replication factor of the system was 2.8. Next version of f4, introduced XOR coding to improve fault-tolerance at level of data centers. What is more interesting, XOR coding lowered replication factor. Instead of replicating cells we take blocks from one cell (data center A), pair it with blocks from another (different!) cell (data center B) and XOR them together forming parity blocks at data center C. In this way system can still tolerate failure of one data center but at lower replication factor of 2.1.
There is some additional loss of space due to soft-deletions which measures at 6.8% according to the paper. Volumes are immutable but deletions are supported thanks to soft deletions - only encryption keys (kept outside of volume) are deleted and make data unreadable.
Unfortunately there is no insight into why they decided to have two versions of f4 system, one with RS(10, 4) and one with XOR coding introduced on top of it. I mean, since they decided to implement distributed erasure coding why not to use it on all failure domains? Maybe that’s because of throughput requirements?
Distributed erasure coding and geo-replicated XOR coding is heart of the system. That was my reason to read the paper in the first place.
There are other components of the system like name nodes, backoff nodes, rebuilder nodes, but it’s more or less standard stuff. I’ll skip it. Coordinator nodes are more interesting because they arrange where data blocks are going to be placed in order to minimize chance of data unavailability. This needs to happen when volume is migrated from Haystack to f4. Rebalancing of data blocks needs to be performed when failures impact the system or when hosts are added or removed.
Things that grabbed my attention
- Definitely distributed erasure coding and geo-replicated XOR coding.
- Early version of f4 used journal to keep track of deletes, but it didn’t play well with Hadoop File System they have used at heart of their implementation. They have finally moved tracking of deletes to external system outside of HDFS.
- Initially they had throughput issues while using HDFS. Each node in HDFS can serve request for a file but read is proxied to correct node. Apparently Java multithreading did not scale well to a large number of parallel requests resulting in an increasing backlog of network IO.
- A lot of interesting references to other papers and systems were made, I’ll be definitely checking out at least some of them.

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.